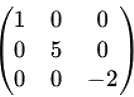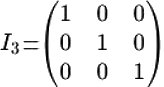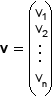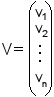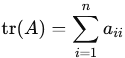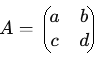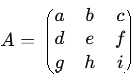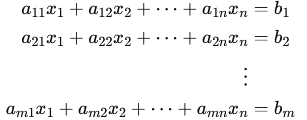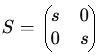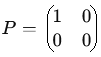| . |
|
||||||
|
|
| . |
|
||||||
| La pensÊe et ses outils > Logique et thÊorie de la connaissance > MathÊmatiques > Algèbre |
L'algèbre
linĂŠaire est un domaine des mathĂŠmatiques qui ĂŠtudie les vecteurs,
les espaces vectoriels, les transformations linĂŠaires, les matrices et
les systèmes d'Êquations linÊaires. Elle est est aujourd'hui un outil
fondamental dans divers domaines, comme la physique thĂŠorique (espaces
de Hilbert en mĂŠcanique quantique), l'informatique
(intelligence artificielle,
traitement d'images, apprentissage automatique), l'ĂŠconomie (modĂŠlisation
linĂŠaire et optimisation), le gĂŠnie civil et l'architecture (calculs
de structures), etc.
Notions gÊnÊrales sur les vecteursUn vecteur v est une entitÊ mathÊmatique qui combine deux caractÊristiques essentielles- : une magnitude (norme ou module) et un sens, et qui peut se prÊsenter comme une liste ordonnÊe de nombres, appelÊs composantes ou coordonnÊes du vecteur. Ces nombres dÊcrivent la position d'un point et une direction et un sens dans un espace. Par exemple, en 2 dimensions : v = (x, y); en 3 dimensions : v = (x, y, z); en n dimensions : v = (v1, v2,..., vn).ReprÊsentation gÊomÊtrique. Les notions abordÊes ici le seront de manière intuitive. On y reviendra de manière plus rigoureuse dans la section consacrÊe aux espaces euclidiens. Vecteur
en 2D.
Vecteur
en 3D.
Norme.
Sens.
OpĂŠrations sur
les vecteurs.
L'addition de deux vecteurs (et a fortiori de plusieurs vecteurs) possède plusieurs propriÊtÊs importantes : ⢠Fermeture. - L'addition de deux vecteurs quelconques de E est un vecteur de E : u + vGrâce à la commutativitÊ et l'associativitÊ, on peut rÊarranger les termes d'une somme de vecteurs à notre convenance pour faciliter les calculs. L'existence d'un ÊlÊment neutre et, pour tout vecteur, celle d'un vecteur opposÊ permet de dÊfinir la soustraction (notÊe -) de deux vecteurs : la soustraction d'un vecteur est dÊfinie comme l'addition de son opposÊ : u - v = u + (-v). Multiplication
par un scalaire.
La multiplication
scalaire est associative (k(l.u) = (kl).u), distributive
par rapport Ă l'addition vectorielle (k.(u + v) = k.u
+ k.v) et distributive par rapport Ă l'adition des scalaires ((k
+ l.).u = k.u + l.u). Il existe dans l'ensemble K
un ĂŠlĂŠment neutre (notĂŠ ici 1), tel que pour tout l'ĂŠlĂŠment
u
de E, on ait 1.u = u et u.1 = u, et un ĂŠlĂŠment
absorbant (notĂŠ 0), tel que que pour tout u Autres
opĂŠrations.
⢠Produit scalaire. - Le produit scalaire (notÊ .) est une opÊration qui donne un nombre à partir de deux vecteurs : u.v = k. ⢠Produit matriciel (d'un vecteur par une matrice). - Une matrice A de taille m x n multipliÊe par un vecteur v de dimension n donne un vecteur w de dimension m. Chaque composante de w est le produit scalaire d'une ligne de A par le vecteur v.Relations gÊomÊtriques entre vecteurs. En gÊomÊtrie vectorielle, plusieurs relations importantes existent entre les vecteurs. Leurs dÊfinitions sont indÊpendantes du choix de l'origine des vecteurs, car on s'intÊresse aux relations entre les directions, sens et normes : Vecteurs
ĂŠquipollents (ĂŠgaux).
Vecteurs
orthogonaux (perpendiculaires).
Vecteurs
colinÊaires (parallèles).
Vecteurs
opposĂŠs.
Espaces vectorielsLa notion d'espace vectoriel est au coeur de l'algèbre linÊaire. C'est une abstraction puissante qui sous-tend une grande partie des mathÊmatiques et des sciences modernes.DÊfinition.
Les premiers sont les vecteurs : un espace vectoriel E est une ensemble de vecteurs.Mettons de côtÊ les dÊfinitions du produit scalaire et du produit vectoriel donnÊes prÊcÊdemment, on dispose dÊjà pratiquement tout ce qu'il faut pour dÊfinir un espace vectoriel. Il ne reste qu'à prÊciser quelques contraintes particulières : ⢠E est un groupe abÊlien. - Pour commencer l'addition de deux vecteurs doit doter E d'une structure de groupe abÊlien (loi + interne, commutative, associative, exsitence d'un ÊlÊment neutre et existence pour tout ÊlÊment d'un symÊtrique).Si ces conditions sont rÊunies, on dit que E, muni d'une opÊration interne et d'une opÊration externe dont le domaine d'opÊrateurs est K, a une structure d'espace vectoriel sur K, ou que E est un espace vectoriel (sur K), ou encore que E est un K-espace vectoriel. Combinaison linÊaire,
indĂŠpendance linĂŠaire, base et dimension.
Si v1, v2,âŚ, vkâ sont des vecteurs dans V et Îť1, Îť2,âŚ, Îťk sont des scalaires dans K, alors w = Îť1v1 + Îť2v2 +... + Îťkvk est une combinaison linĂŠaire de v1, v2,âŚ,vk. IndĂŠpendance
linĂŠaire.
Un ensemble de vecteurs
{v1, v2, âŚ, vk}
dans V est dit linĂŠairement indĂŠpendant si la seule combinaison linĂŠaire
qui donne le vecteur nul est celle oĂš tous les coefficients sont nuls
: Îť 1v1 + Îť2v2
+
... + Îťkvk =
0â
â Si au moins un des coefficients peut ĂŞtre non nul dans une telle combinaison donnant le vecteur nul, les vecteurs sont dits linĂŠairement dĂŠpendants. Dans ce cas, au moins un des vecteurs peut ĂŞtre ĂŠcrit comme une combinaison linĂŠaire des autres. Base
d'un espace vectoriel.
Un ensemble de vecteurs BV = {b1, b2,âŚ, bn} est une base de l'espace vectoriel V si : a) l'ensemble {b1, b2,âŚ, bn} est linĂŠairement indĂŠpendant;Une base est ainsi un ensemble de vecteurs Ă la fois minimal (aucun vecteur ne peut ĂŞtre retirĂŠ sans perdre l'indĂŠpendance linĂŠaire) et maximal (aucun vecteur supplĂŠmentaire ne peut ĂŞtre ajoutĂŠ sans perdre l'indĂŠpendance linĂŠaire). Dimension d'un espace vectoriel. La dimension d'un espace vectoriel est le nombre de vecteurs dans une base de cet espace. Si V est un espace
vectoriel et {b1, b2,âŚ,
bn}
est une base de V, alors la dimension de V est dimâĄ(V) = n. Par exemple, Toutes les bases d'un espace vectoriel ont le mĂŞme nombre de vecteurs. Dans un espace vectoriel de dimension finie V, tout ensemble linĂŠairement indĂŠpendant peut ĂŞtre complĂŠtĂŠ pour former une base. Si dimâĄ(V) = n, alors tout ensemble de n vecteurs linĂŠairement indĂŠpendants dans V est une base, et tout ensemble de n vecteurs qui engendrent V est aussi une base. Sous-espaces vectoriels.
Un sous-ensemble W d'un espace vectoriel V sur un corps K est un sous-espace vectoriel si les conditions suivantes sont remplies : ⢠W âCaractĂŠrisation par combinaison linĂŠaire. Si W est un sous-espace vectoriel, alors tout vecteur de W peut s'ĂŠcrire comme une combinaison linĂŠaire de vecteurs d'une base de W. L'ensemble de toutes les combinaisons linĂŠaires de v1, v2,âŚ,vk.â forme un sous-espace vectoriel de W appelĂŠ espace engendrĂŠ par {v1,v2,âŚ, vk}. Intersection
des sous-espaces.
Somme
des sous-espaces.
Dimension.
StabilitĂŠ
par restriction.
Exemples.
L'ensemble des polynĂ´mes de degrĂŠ infĂŠrieur ou ĂŠgal Ă n, notĂŠ Pn, est un sous-espace vectoriel de l'ensemble des polynĂ´mes P. Espace vectoriel
des fonctions rĂŠelles.
L'espace vectoriel des fonctions rĂŠelles est de dimension infinie. Cela signifie qu'il n'existe pas de base finie pour cet espace. En d'autres termes, on ne peut pas exprimer toutes les fonctions rĂŠelles comme une combinaison linĂŠaire d'un nombre fini de fonctions. Il existe de nombreux sous-espaces vectoriels importants dans l'espace des fonctions rĂŠelles, tels que : l'espace des fonctions continues, l'espace des fonctions dĂŠrivables, l'espace des fonctions intĂŠgrables, l'espace des polynĂ´mes, l'espace des fonctions pĂŠriodiques, etc. Applications linĂŠairesLes applications (ou transformations) linĂŠaires sont des fonctions qui transforment des vecteurs tout en conservant les propriĂŠtĂŠs d'additivitĂŠ et d'homogĂŠnĂŠitĂŠ. Par exemple, la rotation, l'ĂŠtirement ou la rĂŠflexion.DĂŠfinition et
propriĂŠtĂŠs.
f(u + v) = f(u) + f(v) pour tous u, vCes propriĂŠtĂŠs garantissent que f prĂŠserve les relations linĂŠaires entre les vecteurs. Image
d'une application linĂŠaire.
L'image de f est un sous-espace vectoriel de W. La dimension de Im(f) est appelĂŠe le rang de f, notĂŠ rang(f). Noyau
d'une application linĂŠaire.
Le noyau de f est un sous-espace vectoriel de V. Si f est injective, alors Ker(f) = {0}. La dimension de Ker(f) est appelÊe la nullitÊ de f, notÊe null(f). ThÊorème du
rang
dimâĄ(V) = rang(f) + null(f).InterprĂŠtation : ⢠rang(f) reprĂŠsente le nombre de dimensions de V qui "contribuent" rĂŠellement Ă l'image.Isomorphismes. En algèbre linĂŠaire, un isomorphisme est une application linĂŠaire qui ĂŠtablit une correspondance biunivoque (bijective) entre deux espaces vectoriels. Soient V et W deux espaces vectoriels sur un mĂŞme corps K. Une application f : V â W est un isomorphisme d'espaces vectoriels si elle satisfait les conditions suivantes : ⢠LinĂŠaritĂŠ :Ces deux dernières conditions combinĂŠes expriment la bijectivitĂŠ de f. Si deux espaces vectoriels V et W sont isomorphes, cela signifie qu'ils ont la mĂŞme structure algĂŠbrique, mĂŞme s'ils peuvent apparaĂŽtre diffĂŠrents Ă première vue (par exemple, leurs bases peuvent ĂŞtre diffĂŠrentes). Concrètement, cela revient Ă dire qu'ils ont la mĂŞme dimension et les mĂŞmes propriĂŠtĂŠs algĂŠbriques. Les isomorphismes conservent en particulier les opĂŠrations d'addition et de multiplication scalaire. Si V et W sont isomorphes, alors ils ont mĂŞme dimension : dimâĄ(V) = dimâĄ(W). Si f : VâW est un isomorphisme, alors son inverse fâ1 : WâV est ĂŠgalement linĂŠaire. Matrices et reprĂŠsentation des applications linĂŠairesDĂŠfinitions.DĂŠfinition d'une matrice. Une matrice est un tableau rectangulaire d'ĂŠlĂŠments, gĂŠnĂŠralement des nombres (et plus largement d'ĂŠlĂŠments d'un corps K) , disposĂŠs en lignes et en colonnes. On la reprĂŠsente entre crochets [] ou parenthèses (). Dimensions
(lignes, colonnes).
L'ensemble des matrices m x n dont les ĂŠlĂŠments appartiennent Ă un corps K pourra ĂŞtre notĂŠ : Mm x n (K). Types
de matrices.
⢠Matrice carrÊe. - Une matrice carrÊe est une matrice avec un nombre Êgal de lignes et de colonnes (m = n). On parle alors d'une matrice de taille n x n ou d'ordre n. ⢠Matrice triangulaire. - Une matrice triangulaire est une matrice carrÊe dont tous les ÊlÊments au-dessus ou au-dessous de la diagonale principale sont nuls.Notations des ÊlÊments d'une matrice.+ Matrice triangulaire supÊrieure. - Tous les ÊlÊments en dessous de la diagonale sont nuls. Les ÊlÊments d'une matrice sont gÊnÊralement notÊs à l'aide d'une lettre minuscule, souvent a, suivie de deux indices. Le premier indice indique le numÊro de la ligne, et le second indice indique le numÊro de la colonne oÚ se trouve l'ÊlÊment. Si on considère une matrice A de dimension m x n, on note ses ÊlÊments aij, oÚ : i reprÊsente le numÊro de la ligne (1 ⤠i ⤠m), et j reprÊsente le numÊro de la colonne (1 ⤠j ⤠n).
a11 est l'ÊlÊment situÊ à la ligne 1 et à la colonne 1, a12 est l'ÊlÊment situÊ à la ligne 1 et à la colonne 2, a21 est l'ÊlÊment situÊ à la ligne 2 et à la colonne 1, etc. On peut Êgalement utiliser d'autres lettres minuscules comme bij, cij, etc., pour reprÊsenter les ÊlÊments de matrices diffÊrentes. L'important est de maintenir une notation cohÊrente tout au long d'un calcul ou d'une dÊmonstration. La matrice elle-même est gÊnÊralement reprÊsentÊe par une lettre majuscule (A, B, C, etc.). OpÊrations sur les matrices. Addition et soustraction de matrices (conditions). L'addition et la soustraction de matrices ne sont dÊfinies que pour les matrices de mêmes dimensions. Si deux matrices A et B ont la même dimension m x n, alors leur somme (A + B) et leur diffÊrence (A - B) sont Êgalement des matrices m x n dont les ÊlÊments sont calculÊs ÊlÊment par ÊlÊment. ⢠Addition de matrices. - Soient A et B deux matrices m x n : A = [aij] et B = [bij], alors, la matrice somme C = A + B est dÊfinie par : C = [cij] oÚ cij = aij + bij pour tout i et j. ⢠Soustraction de matrices. - La soustraction est similaire à l'addition. Soient A et B deux matrices m x n : A = [aij] et B = [bij]. Alors, la matrice diffÊrence D = A - B est dÊfinie par : D = [dij] oÚ dij = aij - bij pour tout i et j.L'addition de matrices est commutative (A + B = B + A); associative ((A + B) + C = A + (B + C)), et elle possède un ÊlÊment neutre: La matrice nulle (de même dimension). Multiplication
d'une matrice par un scalaire.
La multiplication d'une matrice par un scalaire possède les propriĂŠtĂŠs suivantes : ⢠AssociativitĂŠ : k.(l.A) = (kl).A oĂš k et l sont des scalaires.Produit de deux matrices. Le produit matriciel consiste Ă "multiplier" deux matrices pour obtenir une troisième matrice. Ce n'est pas une opĂŠration ĂŠlĂŠment par ĂŠlĂŠment comme l'addition matricielle. Si A = [aik] et B = [bkj], alors le produit C = [cij] = A.B est une matrice m x p oĂš l'ĂŠlĂŠment cij est calculĂŠ comme la somme des produits des ĂŠlĂŠments correspondants de la i-ème ligne de A et de la j-ème colonne de B : 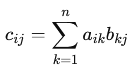 oĂš aikâ est l'ĂŠlĂŠment de la i-ème ligne et k-ième colonne de A, et bkjâ est l'ĂŠlĂŠment de la k-ième ligne et j-ième colonne de B. PropriĂŠtĂŠs : ⢠Non-commutativitĂŠ : en gĂŠnĂŠral, AB â BA. L'ordre est crucial, et demande une attention particulière. MĂŞme si AB et BA sont dĂŠfinies, elles ne sont pas forcĂŠment ĂŠgales.Le produit par une matrice diagonale est simple : il effectue une mise Ă l'ĂŠchelle des lignes ou des colonnes selon les valeurs diagonales. Le produit matriciel peut ĂŞtre interprĂŠtĂŠ comme une transformation gĂŠomĂŠtrique. Chaque matrice peut reprĂŠsenter une transformation linĂŠaire (rotation, dilatation, projection, etc.). Le produit de deux matrices reprĂŠsente alors la composition de ces transformations. Par exemple, si A reprĂŠsente une rotation et B une dilatation, alors AB reprĂŠsente d'abord une dilatation suivie d'une rotation. L'ordre est important car la rotation puis la dilatation donnerait un rĂŠsultat diffĂŠrent (BA). Transposition
d'une matrice.
PropriÊtÊs importantes de la transposÊe : ⢠TransposÊe de la transposÊe d'une matrice : (AT)T = A.Matrices particulières : ⢠Matrice symÊtrique. - Une matrice symÊtrique est une matrice carrÊe qui est Êgale à sa transposÊe (A = AT). Cela signifie que les ÊlÊments aij et aji sont Êgaux pour tous i et j.Inversion d'une matrice. L'inversion d'une matrice A consiste à calculer une matrice inverse notÊe A-1, telle que A.A-1 = A-1.A = I, oÚ I est la matrice identitÊ. On reviendra plus bas sur les conditions que doir remplir une matrice pour être inversible, et si c'est le cas sur la manière de calculer son inverse. Notons seulement des propriÊtÊs importantes de l'inverse : ⢠Inverse de l'inverse d'une matrice : (A-1)-1 = AVecteurs, matrices et applications linÊaires. Les paragraphes prÊcÊdents ont montrÊ la relation Êtroite qui exsite entre les vecteurs et les applications linÊaires. Il reste a Êclairer en quelque mots celle des vecteurs avec les matrices et, par là , celle des matrices avec les applications linÊaires. On peut voir les vecteurs comme un cas particulier de matrices, et les matrices comme des outils pour manipuler les vecteurs de manière efficace en reconnaissant qu'elles sont une expression des applications linÊaires.. Les
matrices peuvent ĂŞtre considĂŠrĂŠes comme des vecteurs.
Les
vecteurs peuvent ĂŞtre considĂŠrĂŠs comme des matrices.
Cela ressemble Ă
une matrice de dimension n x 1 (comme la première Êcriture ressemblait
Ă celle d'une matrice de dimension 1 x n). Nous parlons de ressemblance,
parce que dans la pratique (et cela se justifie par les contextes et les
manières dans lesquels les uns et les autres sont utilisÊs), on a l'habitude
de distinguer les entitĂŠs nommĂŠes proprement vecteurs de ce type particulier
de vecteurs (ĂŠlĂŠments d'un espace vectoriel) que sont les matrices.
La distinction se fait par des diffĂŠrences de notation et de vocabulaire.
Un vecteur colonne est ainsi une matrice composĂŠe d'une seule colonne
de nombres. Si l'on a un vecteur
v qui est un ĂŠlĂŠment d'un espace
vectoriel, alors le vecteur colonne V correspondant Ă v est simplement
la reprĂŠsentation de
v sous forme de matrice colonne. Un vecteur
colonne est une matrice de dimension n x 1, tandis qu'un vecteur ligne
est une matrice de dimension 1 x n. Cela permet d'utiliser les opĂŠrations
matricielles (addition, multiplication) sur les vecteurs.
Les
matrices sont l'expression d'applications linĂŠaires.
On peut dès lors voir dans une matrice A l'expression d'une application linĂŠaire f. Le produit d'un vecteur v par une matrice A (soit A.v) reprĂŠsente une transformation linĂŠaire du vecteur. On qualifie aussi une telle matrice d'opĂŠrateur sur les vecteurs. La matrice dĂŠcrit cette transformation (rotation, dilatation, cisaillement, etc.), et le vecteur w rĂŠsultant est l'image du vecteur original après cette transformation. Composition d'applications linĂŠaires et produit matriciel. ConsidĂŠrons une application linĂŠaire f : VnâWm. (les indices n et m reprĂŠsentant la dimension de chaque espace). Cette application pourra ĂŞtre reprĂŠsentĂŠe par une matrice A de dimension mĂn. Si x La composition gof des deux applications linĂŠaires, dĂŠfinie comme : (gof)(x) = g(f(x)), peut alors s'exprimer termes de matrices comme (gOf)(x) = B.(A.x). Le produit B.(A.x) peut ĂŞtre aussi rĂŠĂŠcrit comme : (B.A).x,, oĂš B.A est le produit matriciel des matrices B et A. La matrice C = B.A reprĂŠsente dès lors la composition gOf, et elle est de dimension pĂn, ce qui correspond Ă une application Vn â Zp. Le produit matriciel n'est pas commutatif, et l'ordre de multiplication B.A reflète l'ordre de la composition gOf. La composition d'applications linĂŠaires est associative, tout comme le produit matriciel : (hOg)Of = hO(gOf) et (C.B).A = C.(B.A). Domaine, noyau,
image, dimension, rang, trace.
Noyau.
Image.
Lien
entre noyau, image et dimension.
dim(Im(A)) + dim(Ker(A)) = dim(Dom(A)), soit : rang(A)+null (A) = n. oÚ n est le nombre de colonnes de la matrice A (dimension de l'espace de dÊpart). Cela signifie que la somme des dimensions de l'image (rang) et du noyau (nullitÊ) est Êgale au nombre total de variables dans le système. Le rang d'une matrice est Êgal au rang de sa transposÊe : rang(A) = rang(AT). Le rang d'une matrice est au plus Êgal au minimum de son nombre de lignes et de son nombre de colonnes. Trace
d'une matrice.
oÚ aii sont les ÊlÊments diagonaux de A. PropriÊtÊs de la trace : ⢠LinÊaritÊ : tr(A + B) = tr(A) + tr(B); tr(cA) = c.tr(A), pour un scalaire c.OpÊrations ÊlÊmentaires. On appelle opÊrations ÊlÊmentaires (sur les lignes) d'une matrice des manipulations utilisÊes pour simplifier une matrice tout en prÊservant son contenu mathÊmatique essentiel. Ce sont principalement : l'Êchange (permutation) de deux lignes, la multiplication d'une ligne par un scalaire non nul, l'ajout (ou la soustraction) d'un multiple d'une ligne à une autre et l'ajout tous les ÊlÊments d'une ligne à une autre ligne. Ces opÊrations prÊservent notamment le rang, la trace, le noyau et l'image de la matrice concernÊe. Augmentation d'une matrice L'augmentation d'une matrice est l'opÊration consistant à ajouter une ou plusieurs colonnes (ou Êventuellement des lignes) à une matrice existante pour former une nouvelle matrice, appelÊe matrice augmentÊe : soit une matrice A de coefficients et une matrice de constantes B; la matrice augmentÊe pourra se noter [A | B] ou (A |B). La matrice augmentÊe (A | B) a les propriÊtÊs suivantes : elle a le même nombre de lignes que la matrice A; elle a un nombre de colonnes Êgal au nombre de colonnes de A plus le nombre de colonnes de B; les ÊlÊments de la matrice A sont conservÊs dans la matrice augmentÊe; la colonne de constantes B est ajoutÊe à la fin de la matrice A. Contrairement à ce qui se passe avec les opÊrations ÊlÊmentaires vues prÊcÊdemment, l'augmentation d'une matrice transforme les propriÊtÊs de base de la matrice de dÊpart. Mais c'est une technique utile pour intÊgrer des informations supplÊmentaires dans une matrice, notamment pour la rÊsolution de systèmes d'Êquations linÊaires ou l'analyse de la dÊpendance linÊaire entre les vecteurs ou les lignes d'une matrice, par exemple. Matrice de changement
de base. Matrice de passage.
Si un vecteur v est exprimĂŠ dans une base B1 et que l'on veut exprimer ce mĂŞme vecteur dans une autre base B2â, une matrice de passage PB1âB2 permet de faire cette conversion. Elle satisfait la relation : [v]B2= PB1âB2.[v]B1 , oĂš [v]B1ââ sont les coordonnĂŠes du vecteur v dans la base B1â, [v]B2ââ sont les coordonnĂŠes du vecteur v dans la base B2â, PB1âB2ââ est la matrice de passage de la base B1 Ă la base B2â. Pour construire la matrice de passage PB1âB2â, on exprime les vecteurs de la base B2â dans la base B1, c'est-Ă -dire que l'on prend chaque vecteur de la base B2â et on les exprime comme une comme une combinaison linĂŠaire des vecteurs de B1â. Les colonnes de PB1âB2ââ sont alors les coordonnĂŠes des vecteurs de B2â dans B1â. DĂŠterminantsDĂŠfinition.Le dĂŠterminant est une fonction qui associe Ă une matrice carrĂŠe un nombre rĂŠel ou complexe (selon le corps de dĂŠfinition de la matrice). Ce nombre (auquel on donne aussi le nom de dĂŠterminant par abus de langage), notĂŠ detâĄ(A) ou |A|, est un invariant fondamental qui contient des informations clĂŠs sur les propriĂŠtĂŠs de la matrice. Le calcul d'un dĂŠterminant d'une matrice carrĂŠe repose sur la somme alternĂŠe des produits des ĂŠlĂŠments de la matrice, pris selon des permutations de ses colonnes ou lignes, affectĂŠs de signes positifs ou nĂŠgatifs selon la paritĂŠ de la permutation. Pour une matrice 2x2, c'est simplement le produit des ĂŠlĂŠments de la diagonale principale moins le produit des ĂŠlĂŠments de l'autre diagonale. Pour des matrices plus grandes, on utilise souvent le dĂŠveloppement par rapport Ă une ligne ou une colonne, rĂŠduisant ainsi le calcul Ă des dĂŠterminants de sous-matrices plus petites. Exemples
de dĂŠterminants faciles Ă calculer.
⢠Pour une matrice 2Ă2 :PropriĂŠtĂŠs ĂŠlĂŠmentaires des dĂŠterminants. DĂŠterminant de la matrice identitĂŠ. Inâ ĂŠtant la matrice identitĂŠ de taille nĂn, on a detâĄ(In) = 1. Multiplication
des dĂŠterminants.
DĂŠterminant
d'une transposĂŠe.
Ăchange
de lignes ou de colonne.
LinĂŠaritĂŠ
par rapport Ă une ligne ou une colonne.
Lignes
ou colonnes identiques.
Ligne
ou colonne nulle.
Multiplication
d'une ligne ou d'une colonne par un scalaire.
Facteur
commun dans une ligne ou colonne.
Inversion d'une
matrice.
Dans le cas d'une matrice carrĂŠe; l'existence du matrice inverse dĂŠpend de la valeur du dĂŠterminant de la matrice considĂŠrĂŠe : une matrice carrĂŠe A est inversible si et seulement si son dĂŠterminant est non nul : detâĄ(A) â 0. (Si detâĄ(A) = 0, on dit que la matrice est singulière; elle n'a pas d'inverse). Si A est inversible, alors : detâĄ(Aâ1) = 1/detâĄ(A). Inversion
d'une matrice par la mĂŠthode de Gauss Jordan.
Ătapes de la mĂŠthode de Gauss-Jordan : 1) CrĂŠation de la matrice augmentĂŠe. - On crĂŠe une matrice augmentĂŠe en ajoutant la matrice identitĂŠ de mĂŞme taille Ă la droite de la matrice d'origine.Condition d'indĂŠpendance linĂŠaire de vecteurs. Le dĂŠterminant peut ĂŞtre utilisĂŠ comme critère pour vĂŠrifier l'indĂŠpendance linĂŠaire d'un ensemble de vecteurs dans un espace vectoriel Un ensemble de vecteurs {v1, v2,âŚ, vn} dans un espace vectoriel de dimension n est dit linĂŠairement indĂŠpendant si l'ĂŠquation c1âv1â + c2âv2â +âŻ+ cnâvnâ = 0 n'admet comme solution que c1 = c2 =... = cn = 0. Autrement dit, aucun vecteur de cet ensemble ne peut ĂŞtre exprimĂŠ comme une combinaison linĂŠaire des autres. Si les vecteurs v1, v2,âŚ, vnâ sont reprĂŠsentĂŠs par les colonnes d'une matrice carrĂŠe A de dimension nĂn, alors les vecteurs sont linĂŠairement indĂŠpendants si et seulement si detâĄ(A) â 0. (Si detâĄ(A) = 0, les vecteurs sont linĂŠairement dĂŠpendants). Cela vient de ce
que le dĂŠterminant de la matrice A est un indicateur de l'inversibilitĂŠ
de cette matrice. Si detâĄ(A) â 0, la matrice est inversible, ce qui
signifie que ses colonnes (ou ses lignes) forment une base de Systèmes d'Êquations LinÊairesIntroduction aux systèmes linÊaires.Un système d'Êquations linÊaires est un ensemble d'Êquations linÊaires qui doivent être satisfaites simultanÊment. Chaque Êquation linÊaire est une Êquation de la forme : am1x + am2y +... + amnz = b, oÚ am1, am2,..., an sont les coefficients constants de la m-ième Êqation du système; x, y,..., z sont des variables, et b est une constante. ThÊorème
de RouchĂŠ-Capelli.
Soit un système d'Êquations linÊaires de la forme : AX = B, oÚ A est une matrice de coefficients, X est une matrice de variables et B est une matrice de constantes. Le thÊorème de RouchÊ-Capelli Ênonce que : ⢠Si le rang de la matrice A est Êgal au rang de la matrice augmentÊe [A | B], alors le système a une seule solution qui satisfait toutes les Êquations du système.Systèmes homogènes et non homogènes. Les systèmes d'Êquations linÊaires peuvent être classÊs en deux catÊgories : les systèmes homogènes et les systèmes non homogènes. ⢠Systèmes d'Êquations linÊaires homogènes. - Un système d'Êquations linÊaires homogène est un système oÚ toutes les Êquations ont une forme similaire, avec des coefficients constants et des variables, mais sans termes constants. En d'autres termes, toutes les Êquations ont la forme : a1x + a2y +... + anz = 0, oÚ a1, a2,..., an sont des coefficients constants, x, y,..., z sont des variables. Les systèmes homogènes ont les propriÊtÊs suivantes : ils ont toujours au moins une solution, qui est la solution nulle (x = y = z = 0); s'ils ont une solution non nulle, alors ils ont une infinitÊ de solutions; les solutions sont des combinaisons linÊaires des solutions fondamentales. ⢠Systèmes d'Êquations linÊaires non homogènes. - Un système d'Êquations linÊaires non homogène est un système oÚ au moins une Êquation a un terme constant non nul. En d'autres termes, au moins une Êquation a la forme : a1x + a2y +... + anz = b, oÚ a1, a2,..., an sont des coefficients constants, x, y,..., z sont des variables, et b est un terme constant non nul. Les systèmes non homogènes ont les propriÊtÊs suivantes : ils peuvent avoir une solution unique, une infinitÊ de solutions, ou aucune solution. Les solutions ne sont pas nÊcessairement des combinaisons linÊaires des solutions fondamentales.Les systèmes homogènes et non homogènes peuvent être rÊsolus à l'aide de mÊthodes similaires, telles que la mÊthode de Gauss, la mÊthode de Cramer, etc. Cependant, les systèmes homogènes sont souvent plus faciles à rÊsoudre, car ils ont toujours une solution nulle et les solutions non nulles sont des combinaisons linÊaires des solutions fondamentales. En revanche, les systèmes non homogènes peuvent avoir des solutions uniques ou infinies, et les solutions ne sont pas nÊcessairement des combinaisons linÊaires des solutions fondamentales. Un système d'Êquations linÊaires peut être reprÊsentÊ de plusieurs manières. La plus Êvidente est l'Êcriture l'une à la suite des autres (ou plutôt les unes sous les autres) :
Il peut être aussi reprÊsentÊ de manière compacte sous forme matricielle. La matrice A des coefficients, multipliÊe par le vecteur colonne X des inconnues, est Êgale au vecteur colonne B des termes constants : A.X = B. La rÊsolution de ce système se ramène alors à des opÊrations matricielles. MÊthodes de rÊsolution.
MĂŠthode
par substitution.
1) Isoler une variable dans l'une des ĂŠquations.MĂŠthode par combinaison linĂŠaire (ou addition). la mĂŠthode par combinaison linĂŠaire consiste Ă additionner ou soustraire les ĂŠquations pour ĂŠliminer une variable. Ătapes : 1) Multiplier les ĂŠquations pour que les coefficients d'une variable soient opposĂŠs.MĂŠthode matricielle (ou mĂŠthode de Gauss). Cette mĂŠthode utilise les matrices pour rĂŠsoudre le système. Ătapes : 1) ReprĂŠsenter le système sous forme matricielle A.X = B, oĂš A est la matrice des coefficients, X le vecteur des inconnues, et B le vecteur des constantes.MĂŠthode de Cramer. Cette mĂŠthode est applicable si le système a autant d'ĂŠquations que de variables et si le dĂŠterminant de la matrice des coefficients n'est pas nul. Ătapes : 1) Ăcrire le système d'ĂŠquations linĂŠaires sous la forme d'une matrice d'ĂŠquations : Ax = b, oĂš A est la matrice des coefficients, x est la matrice des inconnues et b est la matrice des constantes.La mĂŠthode de Cramer est facile Ă mettre en oeuvre avec des outils de calcul numĂŠrique. Cependant, elle nĂŠcessite de calculer plusieurs dĂŠterminants, ce qui peut ĂŞtre coĂťteux en temps de calcul pour les grands systèmes. Elle n'est pas adaptĂŠe pour les systèmes d'ĂŠquations linĂŠaires avec des coefficients non numĂŠriques. MĂŠthodes
itĂŠratives (Jacobi ou Gauss-Seidel).
Jacobi : Chaque variable est calculĂŠe en fonction des valeurs des autres Ă l'itĂŠration prĂŠcĂŠdente.Ces mĂŠthodes convergent sous certaines conditions, par exemple si la matrice des coefficients est strictement diagonale dominante Valeurs propres et vecteurs propresLes valeurs propres et les vecteurs propres d'une matrice rĂŠvèlent des informations sur la transformation linĂŠaire reprĂŠsentĂŠe par cette matrice. Les vecteurs propres sont des vecteurs qui sont seulement mis Ă l'ĂŠchelle (multipliĂŠs par une constante, la valeur propre) par la transformation.Une valeur propre d'une matrice carrĂŠe A est un scalaire tel que l'ĂŠquation suivante est satisfaite : Av=Îťv, oĂš A est une matrice carrĂŠe nĂn, Îť est une valeur propre, et v est un vecteur propre non nul. Un vecteur propre d'une matrice carrĂŠe A est un vecteur non nul qui, lorsqu'il est multipliĂŠ par la matrice A, donne un vecteur colinĂŠaire Ă lui-mĂŞme, multipliĂŠ par la valeur propre correspondante Îť. Le vecteurs propres reprĂŠsentent des directions invariantes sous l'effet de la transformation linĂŠaire dĂŠfinie par A. Si v est un vecteur propre, l'application de A ne change que sa magnitude (par Îť) mais pas sa direction. Les valeurs propres indiquent les facteurs par lesquels les vecteurs propres sont dilatĂŠs ou contractĂŠs lors de la transformation. Pour trouver les valeurs propres et les vecteurs propres d'une matrice carrĂŠe, on suit les ĂŠtapes suivantes : 1) Ăquation caractĂŠristique : l'ĂŠquation Av = Îťv peut ĂŞtre rĂŠĂŠcrite sous la forme : (AâÎťI)v= 0, oĂš I est la matrice identitĂŠ. Pour qu'il existe une solution non triviale (v â 0) le dĂŠterminant de la matrice (AâÎťI) doit ĂŞtre nul : detâĄ(AâÎťI) = 0. Cette ĂŠquation est appelĂŠe ĂŠquation caractĂŠristique. En la rĂŠsolvant, on trouve les valeurs propres Îť. Espaces euclidiens orientĂŠsUn espace euclidien est un espace vectoriel rĂŠel de dimension finie muni d'une opĂŠration interne particulière appelĂŠe produit scalaire qui dĂŠfinit une norme (ou longueur) sur les vecteurs. Les espaces euclidiens sont ordinairement dĂŠfinis sur le corps des nombres rĂŠelsLe produit scalaire. DĂŠfinition. Le produit scalaire (notĂŠ . , ( , ) ou âš , âş) est une opĂŠration qui donne un nombre Ă partir de deux vecteurs. Le produit scalaire entre deux vecteurs u = (u1, u2, âŚ, un) et v = ( v1, v2, âŚ, vn) dans un espace vectoriel rĂŠel 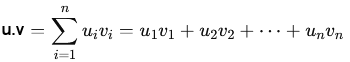 En termes matriciels, le produit scalaire de deux vecteurs u et v, correspond au produit matriciel de la transposĂŠe de u par v : 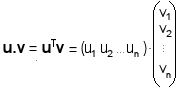 PropriĂŠtĂŠs du produit scalaire. Le produit scalaire est commutatif (u.v = v. u), linĂŠaire par rapport Ă chaque vecteur (u . (k.v) = k.(u.v), (u + v). w = u.w + v.w), et positif dĂŠfini (u.u ⼠0, et u.u = 0 si et seulement si u = 0). Norme, distance
et angle.
||u|| = â(u.u) = â(u1² + u2² +... + un²) Pour tous les vecteurs d'un espace euclidien, on a vĂŠrifie : ⢠La positivitĂŠ : ||u|| ⼠0, avec ||u|| = 0 si et seulement si u = 0.Distance entre deux vecteurs. La distance entre u et v dans Angle
entre deux vecteurs.
||u|| et ||v|| reprĂŠsentent les normes de u et v. OrthogonalitĂŠ
Projection
orthogonale :
Base
orthonormale.
une base (b1,
b2,âŚ,
bn)
de 1) bi.bj =0 pour i â j (orthogonalitĂŠ)Dans une base orthonormale, les coordonnĂŠes d'un vecteur u sont simplement donnĂŠes par les produits scalaires des vecteurs de la base : 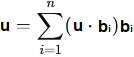 Produit vectoriel
.
Soient deux vecteurs
a et b dans 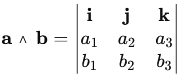 OĂš i, j, k sont les vecteurs unitaires selon les axes x, y et z. Le dĂŠterminant donne : aĂb = (a2b3âa3b2)i â (a1b3âa3b1)j + (a1b2âa2b1)k Le rĂŠsultat aËb est orthogonal Ă a et b. La direction de aËb est dĂŠterminĂŠe par la règle de la main droite : si les doigts de la main droite suivent a vers b, le pouce pointe dans la direction de aËb. La norme du produit vectoriel est donnĂŠe par : ||aËb|| = ||a||.||b||.sinâĄÎ¸, oĂš θ est l'angle entre a et b. Le produit vectoriel est antisymĂŠtrique : aËb = â(bËa) Le produit vectoriel est nul aËb = 0 si et seulement si a//b PropriĂŠtĂŠs
et identitĂŠs remarquables du produit vectoriel.
Formule de Gibbs
(produit mixte avec produits vectoriel et scalaire). - Pour trois vecteurs
u,
v,
w
de IdentitÊ de Jacobi (double produit vectoriel). - L'identitÊ de Jacobi dÊcrit le comportement du double produit vectoriel : u ⧠(v ⧠w) = (u.w)v - (u.v)w. Cette identitÊ est particulièrement utile dans la mÊcanique classique et la thÊorie des champs. IdentitÊ de Lagrange. - Pour deux vecteurs u et v, l'identitÊ de Lagrange donne une relation entre les normes et les produits vectoriel et scalaire : ||u ⧠v||² = ||u||².||v||² - (u.v)². Cela exprime que le carrÊ de la norme du produit vectoriel correspond au dÊterminant du produit mixte des vecteur s. IdentitÊ du triple produit mixte. - Pour trois vecteurs u, v, w, le produit mixte satisfait l'identitÊ suivante : u. (v ⧠w) = v.(w ⧠u) = w. (u ⧠v). Cette ÊgalitÊ montre la cyclicitÊ dans l'expression du produit mixte. Exemples d'applications
linĂŠaires courantes dans R2.
x' = xcosâĄÎ¸âysinâĄÎ¸ et y' xsinâĄÎ¸+ycosâĄÎ¸, soit w = (xcosâĄÎ¸âysinâĄÎ¸, xsinâĄÎ¸+ycosâĄÎ¸), oĂš θ est l'angle de rotation. La matrice de rotation correspondante est donnĂŠe par : 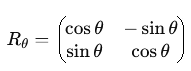 En dimension supĂŠrieure
( Changement
d'ĂŠchelle (homothĂŠtie).
Pour un changement d'ĂŠchelle anisotrope, les facteurs d'ĂŠchelle peuvent ĂŞtre diffĂŠrents dans chaque direction : 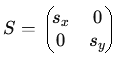 Une projection orthogonale sur une droite dans
RĂŠflexion.
Formes linĂŠaires, bilinĂŠaires et quadratiquesFormes linĂŠaires.Une forme linĂŠaire est une application linĂŠaire d'un espace vectoriel V (sur un corps K, souvent R ou C) vers le corps K. Si f : VâK est une forme linĂŠaire, alors pour tous x,y Le noyau kerâĄ(f)={x Dans V=Rn, une forme linĂŠaire peut ĂŞtre ĂŠcrite comme : f(x) = a1âx1â + a2âx2â +âŻ+ anâxnâ = â¨a,xâŠoĂš a = (a1,âŚ, an) Formes bilinĂŠaires.
B(x+y, z) = B(x,z) + B(y,z) (linÊaritÊ par rapport à la première variable),
On dit qu'une forme bilinĂŠaire est symĂŠtrique si B(x,y) = B(y,x); elle est antisymĂŠtrique si B(x,y) = âB(y,x). La matrice associĂŠe A dĂŠpend de la base choisie dans V. Le produit scalaire est une forme bilinĂŠaire symĂŠtrique et dĂŠfinie positive. Formes quadratiques.
Les formes quadratiques ont des propriÊtÊs telles que : ⢠HomogÊnÊitÊ : La forme quadratique est homogène, c'est-à -dire que pour tous les vecteurs u et pour tous les scalaires a, on a : Q(au) = a2 Q(u)Les formes quadratiques peuvent être : ⢠DÊfinies positives : Si Q(u) > 0 pour tous les vecteurs u non nuls.Le rang d'une forme quadratique est le nombre de valeurs propres non nulles de sa matrice. Le dÊfaut d'une forme quadratique est le nombre de valeurs propres nulles. Le rang et le dÊfaut sont liÊs à la nature de la forme quadratique (dÊfinie positive, dÊfinie nÊgative ou indÊfinie). La signature d'une forme quadratique est le nombre de valeurs propres positives moins le nombre de valeurs propres nÊgatives. Elle est liÊe à la nature de la forme quadratique (dÊfinie positive, dÊfinie nÊgative ou indÊfinie). La forme quadratique euclidienne est une forme quadratique dÊfinie positive qui correspond à la longueur d'un vecteur. La forme quadratique de Lorentz est une forme quadratique qui correspond à la mÊtrique de l'espace-temps en relativitÊ restreinte. |
| . |
|
|
|||||||||||||||||||||||||||||||
|