| Un
arbre
de dÊcision est un modèle d'apprentissage automatique utilisÊ pour
la prise de dĂŠcision et la prĂŠdiction. Il est structurĂŠ en une sĂŠrie
de choix qui se ramifient Ă partir d'un point de dĂŠpart, un peu comme
un arbre avec ses branches. Les arbres de dĂŠcision sont couramment utilisĂŠs
dans les domaines de l'intelligence
artificielle, du marketing, des finances, et bien d'autres pour la
modĂŠlisation et la prise de dĂŠcision. Ils ont l'avantage d'ĂŞtre faciles
Ă comprendre et Ă interprĂŠter, ce qui en fait un outil transparent pour
la prise de dĂŠcision. Ils peuvent gĂŠrer Ă la fois des donnĂŠes catĂŠgoriques
et numÊriques. Contrairement à d'autres modèles, les arbres de dÊcision
n'ont pas besoin que les donnĂŠes soient normalisĂŠes ou mises Ă l'ĂŠchelle.
Ils peuvent saisir des relations complexes entre les variables. Les arbres
de dĂŠcision ont aussi leurs limites : il peuvent ĂŞtre sujets Ă l'overfitting
( = modèle trop ajustÊ aux donnÊes d'entraÎnement), surtout s'ils
deviennent trop complexes; ils peuvent ĂŠgalement privilĂŠgier des attributs
avec plus de valeurs distinctes, ce qui peut biaiser les dĂŠcisions.
Structure de l'arbre.
La structure d'un
arbre de dĂŠcision se compose de plusieurs ĂŠlĂŠments clĂŠs, organisĂŠs
de manière hiÊrarchique.
Noeud
racine.
Le noeud racine
est le point de dÊpart de l'arbre de dÊcision. Il reprÊsente la première
dĂŠcision ou question posĂŠe en fonction d'une caractĂŠristique spĂŠcifique
des donnĂŠes. Exemple : Dans un arbre pour classer des animaux, le noeud
racine pourrait ĂŞtre "L'animal a-t-il des plumes?".
Noeuds
internes.
Les noeuds internes
sont les points de dĂŠcision intermĂŠdiaires dans l'arbre. Chacun de ces
noeuds pose une question basĂŠe sur une caractĂŠristique des donnĂŠes.
Chaque noeud interne a des branches qui reprĂŠsentent les diffĂŠrentes
rĂŠponses possibles Ă la question posĂŠe. Chaque branche conduit Ă un
autre noeud (interne ou feuille). Exemple : Après "L'animal a-t-il
des plumes?", un noeud interne pourrait poser la question "L'animal peut-il
voler?"
Branches.
Les branches sont
les chemins qui relient les noeuds entre eux. Elles reprĂŠsentent les rĂŠsultats
des tests effectuĂŠs dans les noeuds. Exemple : Si la rĂŠponse Ă "L'animal
a-t-il des plumes?" est "Oui", une branche pourrait mener au noeud suivant
avec la question "L'animal peut-il voler ?".
Feuilles.
Les feuilles sont
les noeuds terminaux de l'arbre, c'est-à -dire qu'ils ne mènent à aucun
autre noeud. Chaque feuille reprĂŠsente un rĂŠsultat final ou une dĂŠcision
basĂŠe sur les rĂŠponses aux questions prĂŠcĂŠdentes. Exemple : Une feuille
pourrait indiquer "L'animal est un oiseau" si toutes les conditions menant
Ă cette feuille sont satisfaites.
Chemin.
Un chemin est une
sĂŠquence de branches allant du noeud racine Ă une feuille. Il reprĂŠsente
la sĂŠrie de dĂŠcisions prises pour arriver Ă une conclusion spĂŠcifique.
Exemple : Un chemin complet pourrait ĂŞtre "L'animal a-t-il des plumes?"
â "Oui" â "L'animal peut-il voler?" â "Non" â "L'animal est un
pingouin".
SchĂŠma d'un arbre de dĂŠcision (ultra-simplifiĂŠ)
:
[L'animal a-t-il des plumes ?] â
Noeud racine
/
\
Oui
Non
/
\
[L'animal peut-il voler ?]
[L'animal a-t-il des poils?]
/
\
Oui
Non
â Noeuds internes
/
\
[L'animal est un
oiseau] [L'animal est un pingouin] â
Feuilles
Critères
de division.
Ă chaque noeud
interne, un critère de division est choisi pour sÊparer les donnÊes
en sous-groupes, ce qui peut se faire Ă l'aide de diverses mĂŠthodes (entropie,
gain d'information, etc.).
Profondeur
de l'arbre.
La profondeur de
l'arbre est le nombre de noeuds depuis la racine jusqu'Ă la feuille la
plus ĂŠloignĂŠe. Un arbre plus profond peut modĂŠliser des dĂŠcisions plus
complexes, mais risque ĂŠgalement de surajuster les donnĂŠes (overfitting).
Fonctionnement.
Le fonctionnement
d'un arbre de dĂŠcision consiste Ă prendre des dĂŠcisions ou Ă faire
des prĂŠdictions en passant par une sĂŠrie de tests sur les caractĂŠristiques
des donnĂŠes.
CrĂŠation
de l'arbre de dĂŠcision.
Le processus commence
par la sĂŠlection de la caractĂŠristique la plus discriminante pour ĂŞtre
placĂŠe Ă la racine de l'arbre. Cette caractĂŠristique est choisie en
fonction de critères utilisÊs Êvaluer la qualitÊ des divisions ou des
scissions. Le jeu de donnĂŠes est ensuite divisĂŠ en sous-ensembles basĂŠs
sur les valeurs de la caractĂŠristique sĂŠlectionnĂŠe. Chaque sous-ensemble
sera ensuite analysÊ de manière similaire dans les sous-noeuds. Le choix
du critère dÊpend du type de donnÊes, du problème à rÊsoudre et des
objectifs spĂŠcifiques en termes de performance et d'interprĂŠtabilitĂŠ,
d'oĂš divers modes de construction d'arbres de dĂŠcision. Par exemple :
⢠Gain
d'information (entropie). - L'entropie mesure l'incertitude ou le dĂŠsordre
dans un ensemble de donnĂŠes. Le gain d'information est la rĂŠduction de
l'entropie obtenue après avoir divisÊ les donnÊes sur un attribut donnÊ.
L'objectif est de maximiser le gain d'information Ă chaque ĂŠtape.
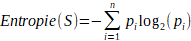
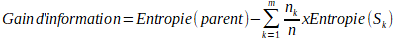
⢠Gain de Gini
(indice de Gini pondĂŠrĂŠ). - L'indice
de Gini mesure la qualitĂŠ de la scission. Le gain de Gini mesure la rĂŠduction
de l'impuretÊ d'une distribution après une scission, et l'objectif est
de minimiser l'indice de Gini pondĂŠrĂŠ. Cela signifie que la scission
choisie maximise l'homogĂŠnĂŠitĂŠ des sous-ensembles par rapport Ă la
variable cible.
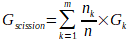
Gscission
est l'indice de Gini de la scission, Gk est l'indice
de Gini du sous ensemble k, nk est le nombre d'ĂŠlĂŠments
dans le sous ensemble k, n est le nombre total d'ĂŠlĂŠments et m est le
nombre de sous-ensembles rĂŠsultants de la scission.
⢠Test du X².
- Le test du X² (khi-deux) est utilisÊ pour Êvaluer si la distribution
des classes dans les sous-ensembles obtenus après une scission est significativement
diffĂŠrente de la distribution attendue. Une valeur ĂŠlevĂŠe du test indique
une bonne division. Ď² = â(OâE)²
/E, oĂš O est la frĂŠquence observĂŠe et E
est la frĂŠquence attendue.
⢠RÊduction
de la variance (pour la rĂŠgression). - UtilisĂŠ dans les arbres
de dĂŠcision pour les tâches de rĂŠgression, cette mĂŠthode cherche Ă
rĂŠduire la variance des valeurs de la variable cible dans les sous-ensembles
rĂŠsultants d'une scission. L'objectif est de minimiser la somme des variances
pondÊrÊes après chaque scission.
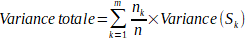
⢠RÊduction
de l'erreur de classification. - L'erreur de classification est
le pourcentage d'exemples mal classĂŠs dans un sous-ensemble. On cherche
Ă rĂŠduire ce chiffre. E(S)=1âmaxâĄ(pi)
oĂš piâ est la proportion de la classe majoritaire.
(Moins souvent utilisĂŠ car il est moins sensible que les au tres mesures,
comme l'entropie ou l'indice de Gini, par exemple).
⢠Forêts alÊatoires.
- Les forĂŞts alĂŠatoires construisent plusieurs arbres de dĂŠcision en
utilisant des ĂŠchantillons alĂŠatoires du jeu de donnĂŠes (bagging)
et en sĂŠlectionnant alĂŠatoirement un sous-ensemble d'attributs Ă chaque
noeud de chaque arbre. Cela introduit de la diversitĂŠ dans les arbres
et rĂŠduit le risque de surapprentissage.
⢠Boosting.
- Dans le boosting, les arbres de dĂŠcision sont construits sĂŠquentiellement,
chaque nouvel arbre cherchant Ă corriger les erreurs commises par les
arbres prĂŠcĂŠdents. Les observations mal classĂŠes dans les arbres prĂŠcĂŠdents
sont pondĂŠrĂŠes davantage dans les arbres suivants.
⢠Arbres de
dĂŠcision obliques. - Contrairement aux arbres classiques qui utilisent
des scissions perpendiculaires aux axes des caractĂŠristiques (i.e., elles
se basent sur un seul attribut Ă la fois), les arbres obliques utilisent
des scissions linĂŠaires qui combinent plusieurs attributs. Cela peut saisir
des relations plus complexes entre les caractĂŠristiques. UtilisĂŠ dans
certaines variantes d'arbres pour la classification multi-dimensionnelle.
ItĂŠration
Ă travers les noeuds internes.
Pour chaque noeud
interne, une nouvelle caractĂŠristique est sĂŠlectionnĂŠe parmi les restantes,
qui divise encore mieux les sous-ensembles de donnĂŠes rĂŠsultants. Cette
sÊlection continue jusqu'à ce que chaque sous-ensemble soit aussi homogène
que possible. Puis les donnĂŠes sont rĂŠparties en fonction des valeurs
de la caractĂŠristique choisie, et les branches sont crĂŠĂŠes pour chaque
valeur ou intervalle de valeurs.
ArrivĂŠe
aux feuilles.
L'algorithme s'arrĂŞte
de crĂŠer de nouveaux noeuds quand l'une des conditions suivantes est remplie
:
⢠Toutes
les donnĂŠes dans un sous-ensemble appartiennent Ă la mĂŞme classe (pour
la classification).
⢠Aucune autre
caractĂŠristique n'est disponible pour la division.
⢠L'arbre a atteint
une profondeur prĂŠdĂŠfinie pour ĂŠviter le surajustement (overfitting).
⢠La feuille finale
est assignĂŠe Ă la classe dominante dans ce sous-ensemble de donnĂŠes,
ou à une valeur moyenne si c'est une tâche de rÊgression.
Utilisation
de l'arbre pour prendre une dĂŠcision.
Pour prĂŠdire la
classe ou la valeur d'une nouvelle donnĂŠe, on commence par le noeud racine
et on parcourt l'arbre en suivant les branches correspondant aux caractĂŠristiques
de la nouvelle donnĂŠe. Une fois qu'une feuille est atteinte, la prĂŠdiction
est faite en fonction de la classe ou de la valeur assignĂŠe Ă cette feuille.
Utilisation.
Les arbres de dĂŠcision
sont utilisĂŠs dans divers domaines pour la classification, la rĂŠgression,
la prise de dĂŠcision, et mĂŞme l'exploration de donnĂŠes :
Classification.
Un arbre de dĂŠcision
peut ĂŞtre utilisĂŠ pour classer des donnĂŠes en diffĂŠrentes catĂŠgories
ou classes. Exemples : classer les patients en fonction de leurs symptĂ´mes
pour prĂŠdire s'ils souffrent d'une certaine maladie; classer les emails
comme ĂŠtant du spam ou non en fonction de certaines caractĂŠristiques
comme le contenu, l'expĂŠditeur, etc.
RĂŠgression.
Les arbres de dĂŠcision
peuvent ĂŠgalement ĂŞtre utilisĂŠs pour la rĂŠgression, c'est-Ă -dire pour
prĂŠdire une valeur continue plutĂ´t qu'une classe. Exemples : prĂŠdire
le prix d'une maison en fonction de caractĂŠristiques comme la superficie,
le nombre de chambres, et l'emplacement; estimer la tempĂŠrature ou les
prĂŠcipitations Ă partir de divers facteurs climatiques.
Prise
de dĂŠcision.
Les arbres de dĂŠcision
peuvent aider Ă prendre des dĂŠcisions en entreprise en modĂŠlisant les
diffĂŠrentes options et leurs consĂŠquences. Exemples : ĂŠvaluer les risques
et les rendements attendus de diffĂŠrents projets d'investissement; dĂŠcider
quelles campagnes publicitaires lancer en fonction des donnĂŠes dĂŠmographiques
et des comportements des consommateurs.
Analyse
prĂŠdictive.
Utiliser les arbres
de dĂŠcision pour prĂŠvoir des ĂŠvĂŠnements futurs ou des tendances en
se basant sur des donnĂŠes historiques. Exemples : prĂŠdire les ventes
futures en fonction des tendances passĂŠes et des facteurs saisonniers;
identifier les clients susceptibles de quitter un service ou de rĂŠsilier
un abonnement en fonction de leur comportement.
Exploration
de donnĂŠes (data mining).
Les arbres de dĂŠcision
peuvent ĂŞtre utilisĂŠs pour analyser et comprendre des ensembles de donnĂŠes
complexes, en identifiant les relations et les patterns (motifs,
rĂŠgularitĂŠs) cachĂŠs. Exemples : identifier diffĂŠrents segments de clients
basĂŠs sur leurs comportements d'achat et d'autres caractĂŠristiques; repĂŠrer
les transactions suspectes ou les comportements frauduleux en analysant
les donnĂŠes de transactions.
Systèmes
de recommandation.
Utiliser des arbres
de dĂŠcision pour recommander des produits ou des contenus en fonction
des prĂŠfĂŠrences et du comportement des utilisateurs. Exemples : recommander
des films Ă regarder en fonction des films prĂŠcĂŠdemment visionnĂŠs et
des ĂŠvaluations donnĂŠes; suggĂŠrer des produits Ă acheter en fonction
des articles dĂŠjĂ consultĂŠs ou achetĂŠs.
Planification
et optimisation.
Les arbres de dĂŠcision
peuvent ĂŞtre utilisĂŠs pour optimiser des processus et planifier des ressources
en ĂŠvaluant diffĂŠrentes options. Exemples : optimiser les chaĂŽnes
de production en dĂŠcidant quel produit fabriquer en fonction des demandes
prĂŠvisionnelles; dĂŠcider des meilleures routes de livraison en fonction
des coĂťts, des temps de trajet et d'autres facteurs. |
