| Les
acides
nuclĂŠiques (ADN et ARN) sont des macromolĂŠcules biologiques formĂŠes
de phosphore (P), de carbone, d'hydrogène,
d'oxygène et d'azote. Ces atomes sont rÊuunis au sein des acides nuclÊiques
dans des structures appelĂŠes nuclĂŠotides; chaque nuclĂŠotide se
compose d'un sucre pentose (dĂŠsoxyribose pour
l'ADN et ribose pour l'ARN), d'une base azotĂŠe (adĂŠnine, cytosine, guanine
et thymine ou uracile) et d'un groupe phosphate.
ConservĂŠs au fil
de l'ĂŠvolution de tous les organismes vivants, les acides nuclĂŠiques
stockent et transmettent des informations hĂŠrĂŠditaires. Ils portent le
schĂŠma gĂŠnĂŠtique d'une cellule et contiennent des instructions pour
le fonctionnement de la cellule.
Les deux principaux
types d'acides nuclĂŠiques sont l'acide dĂŠsoxyribonuclĂŠique (ADN) et
l'acide ribonuclĂŠique (ARN).
Le flux d'informations
gĂŠnĂŠtiques est gĂŠnĂŠralement : ADN  ARN protĂŠine.
L'ADN dicte la structure de l'ARNm dans un processus connu sous le nom
de transcription, puis l'ARN dicte la structure de la protĂŠine
dans un processus connu sous le nom de traduction. Ceci s'applique
à tous les organismes; cependant, des exceptions à la règle se produisent
avec les virus, dont certains, dĂŠpourvus d'ADN,
ont leur gĂŠnome portĂŠ par leur ARN. ARN protĂŠine.
L'ADN dicte la structure de l'ARNm dans un processus connu sous le nom
de transcription, puis l'ARN dicte la structure de la protĂŠine
dans un processus connu sous le nom de traduction. Ceci s'applique
à tous les organismes; cependant, des exceptions à la règle se produisent
avec les virus, dont certains, dĂŠpourvus d'ADN,
ont leur gĂŠnome portĂŠ par leur ARN.
-
ADN et ARN
L'ADN et l'ARN sont
les macromolĂŠcules les plus importantes pour assurer la continuitĂŠ du
vivant.
L'ADN.
L'ADN contient,
sous la forme de sÊquences particulières de nuclÊotides appelÊes des
gènes,
les instructions d'assemblage des sĂŠquences d'acides aminĂŠs menant Ă
la synthèse des protÊines. Il renferme aussi
le plan gĂŠnĂŠtique de la cellule qui est transmise du parent Ă la progĂŠniture
via la division cellulaire.
L'ADN est le matĂŠriel
gĂŠnĂŠtique prĂŠsent dans tous les organismes vivants, allant des bactĂŠries
unicellulaires aux mammifères multicellulaires.
On le trouve dans le noyau des eucaryotes et dans les organites, les chloroplastes
et les mitochondries. Chez les procaryotes (archĂŠes, bactĂŠries), l'ADN
n'est pas enfermĂŠ dans une enveloppe membraneuse.
L'ADN a une structure
double hĂŠlicoĂŻdale avec les deux brins s'ĂŠtendant dans des directions
opposÊes (antiparallèles), reliÊs par des liaisons hydrogène et complÊmentaires
l'un de l'autre.
Dans l'ADN, les purines
(adĂŠnine et guanine) s'associent aux pyrimidines (cytosine et thymine)
: les paires d'adĂŠnine avec la thymine (A-T) et les paires de cytosine
avec la guanine (C-G).
On donne le nom de
gĂŠnome
Ă l'ensemble du contenu gĂŠnĂŠtique d'une cellule, et l'ĂŠtude des gĂŠnomes
s'appelle la gĂŠnomique. Dans les cellules eucaryotes (contrairement Ă
ce que l'on observe chez les procaryotes), l'ADN forme un complexe avec
des protĂŠines (les histones), pour former la chromatine,
qui est la substance des chromosomes eucaryotes.
Un chromosome peut
contenir des dizaines de milliers de gènes. De nombreux gènes contiennent
les informations nĂŠcessaires Ă la fabrication de produits protĂŠiques;
d'autres gènes codent les produits de l'ARN. L'ADN contrôle toutes les
activitÊs cellulaires en activant ou dÊsactivant les gènes.
-
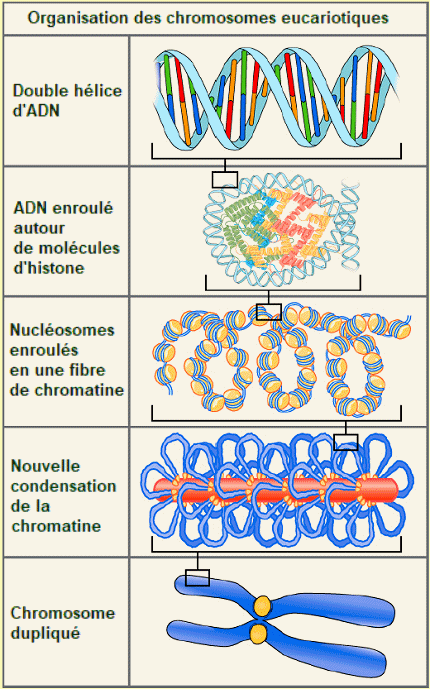
Compactage
d'un chromosome eucaryote. - Chaque chromosome
renferme
une longue molĂŠcule d'ADN, enroulĂŠe Ă des histones. Les
nuclĂŠosomes
contiennent environ 200 paires de nuclĂŠotides.
L'ARN.
Dans l'ARN, l'uracile
remplace la thymine pour s'associer à l'adÊnine (U-A). L'ARN diffère
ĂŠgalement de l'ADN en ce qu'il est Ă simple brin et a de nombreuses formes,
telles que l'ARN messager (ARNm), l'ARN ribosomal (ARNr) et l'ARN de transfert
(ARNt) qui participent tous à la synthèse des protÊines. Les microARN
(miARN) rĂŠgulent l'utilisation de l'ARNm.
Les molĂŠcules d'ADN
ne quittent jamais le noyau mais utilisent plutĂ´t un intermĂŠdiaire pour
communiquer avec le reste de la cellule. Cet intermĂŠdiaire est l'autre
type d'acide nuclĂŠique, l'ARN, en l'occurence l'ARN messager (ARNm), qui
est principalement impliquÊ dans la synthèse des protÊines. D'autres
variĂŠtĂŠs d'ARN : l'ARNt et le microARN, similaires Ă l'ARN, sont
impliquÊs eux aussi dans la synthèse des protÊines et la rÊgulation
de celles-ci.
-
RĂŠsumĂŠ
des caractĂŠristiques de l'ADN et de l'ARN
|
ADN |
ARN |
| Fonction |
Porte
l'information gĂŠnĂŠtique |
Est
impliquÊ dans la synthèse des protÊines |
| Emplacement |
Reste
dans le noyau cellulaire |
Quitte
le noyau |
| Structure |
Double
hĂŠlice |
GĂŠnĂŠralement
Ă simple brin |
| Sucre |
DĂŠsoxyribose |
Ribose |
| Pyrimidines |
Cytosine,
thymine |
Cytosine,
uracile |
| Purines |
AdĂŠnine,
guanine |
AdĂŠnine,
guanine |
Les nuclĂŠotides.
L'ADN et l'ARN sont
constituÊs de monomères appelÊs nuclÊotides. Les nuclÊotides
se combinent les uns aux autres pour former un polynuclĂŠotide, ADN ou
ARN. Chaque nuclĂŠotide a trois composantes : une base azotĂŠe, un sucre
pentose (cinq atomes de carbone) et un groupe phosphate.
Chaque base azotĂŠe d'un nuclĂŠotide est attachĂŠe Ă une molĂŠcule de
sucre, qui elle-mĂŞme est attachĂŠe Ă un ou plusieurs groupes phosphate.
Les
bases azotĂŠes.
Les bases azotĂŠes,
composants importants des nuclĂŠotides, sont des molĂŠcules organiques
et sont ainsi nommĂŠes parce qu'elles contiennent du carbone et de l'azote.
Ce sont des bases car elles contiennent un groupe amino qui a le potentiel
de se lier à un hydrogène supplÊmentaire, diminuant ainsi la concentration
en ions hydrogène dans son environnement, le rendant plus basique.
-
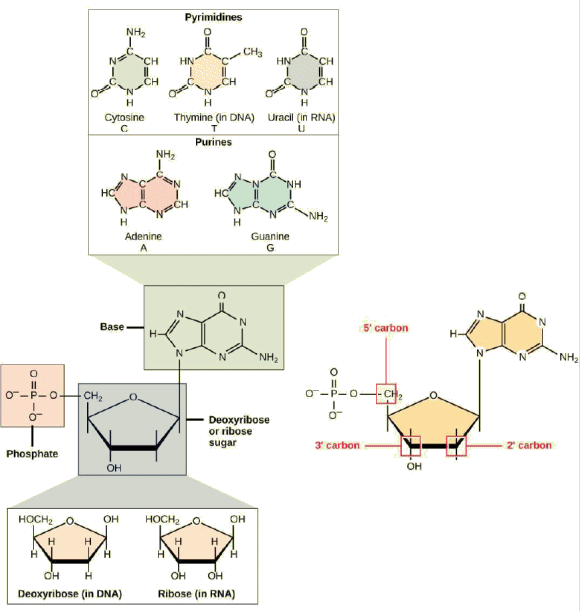
| NuclĂŠotides.
- Un nuclÊotide possède trois composants: une base azotÊe, un sucre
pentose et un ou plusieurs groupes phosphate. En biologie molĂŠculaire,
les bases azotĂŠes sont simplement dĂŠ"signĂŠes par leurs symboles A, T,
G, C et U. L'ADN contient A, T, G et C tandis que l'ARN contient A, U,
G et C. Les rĂŠsidus de carbone dans le pentose sont numĂŠrotĂŠs de 1 'Ă
5' (le prime ' distingue ces rĂŠsidus de ceux de la base, qui sont numĂŠrotĂŠs
sans utiliser de '). La base est attachĂŠe Ă la position 1' du ribose
et le phosphate est attachĂŠ Ă la position 5'. Lorsqu'un polynuclĂŠotide
est formĂŠ, le phosphate 5 'du nuclĂŠotide entrant se fixe au groupe hydroxyle
3' Ă l'extrĂŠmitĂŠ de la chaĂŽne de croissance. On trouve deux types de
pentose dans les nuclĂŠotides, le dĂŠsoxyribose (dans l'ADN) et le ribose
(dans l'ARN). Le dĂŠsoxyribose a une structure similaire au ribose, mais
il a un H au lieu d'un OH en position 2'. Les bases peuvent ĂŞtre divisĂŠes
en deux catĂŠgories: les purines et les pyrimidines. Les purines ont une
structure Ă double cycle et les pyrimidines ont un cycle unique. |
Chaque nuclĂŠotide
de l'ADN contient, on l'a dit, l'une des quatre bases azotĂŠes possibles
: l'adĂŠnine (A), la guanine (G), la cytosine (C) et la thymine (T).
â˘
L'adĂŠnine et la guanine sont rangĂŠes parmi les purines. La structure
primaire d'une purine est constituĂŠe de deux cycles carbone-azote.
⢠La cytosine,
la thymine et l'uracile sont classĂŠes parmi les pyrimidines qui
ont un seul cycle carbone-azote comme structure principale.
Chacun de ces cycles
basiques carbone-azote a diffĂŠrents groupes fonctionnels qui lui sont
attachĂŠs.
Les
sucres et la liaison phosphodiester.
Le sucre pentose
dans l'ADN est le dĂŠsoxyribose, et dans l'ARN, le sucre est le ribose.
La diffĂŠrence entre ces sucres est la prĂŠsence du groupe hydroxyle sur
le deuxième atome de carbone du ribose et de l'atome d'hydrogène sur
le deuxième atome de carbone du dÊsoxyribose.
Les atomes de carbone
de la molĂŠcule de sucre sont numĂŠrotĂŠs comme 1' (lire "un prime"), 2',
3 ', 4' et 5 '. Le rĂŠsidu phosphate est attachĂŠ au groupe hydroxyle de
l'atome de carbone 5' d'un sucre et au groupe hydroxyle de l'atome de carbone
3' du sucre du nuclĂŠotide suivant, qui forme une liaison phosphodiester
5'-3 '.
La liaison phosphodiester
n'est pas formĂŠe par une simple rĂŠaction de dĂŠshydratation comme les
autres liaisons reliant les monomères dans les macromolÊcules : sa formation
implique l'ĂŠlimination de deux groupes phosphate. Un polynuclĂŠotide peut
avoir des milliers de telles liaisons phosphodiester.
Structure et fonction
de l'ADN
Base historique de
la comprĂŠhension moderne.
L'ADN a d'abord
ĂŠtĂŠ isolĂŠ vers 1870 par Friedrich Miescher, qui l'a appelĂŠ nuclĂŠine
parce qu'il ĂŠtait issu de noyaux des globules blancs (Le
sang). Les expĂŠriences, en 1928, de Frederick Griffith avec des souches
de Streptococcus pneumoniae ont fourni le premier indice que l'ADN pourrait
ĂŞtre un principe transformant.
Avery, MacLeod et
McCarty (1944) ont ensuite prouvĂŠ que l'ADN est effectivement requis pour
la transformation des bactĂŠries.
Des expĂŠriences
ultĂŠrieures par Hershey et Chase (1952) utilisant le bactĂŠriophage T2
ont prouvĂŠ que l'ADN constitue le matĂŠriel gĂŠnĂŠtique.
Erwin Chargaff a
constatĂŠ que le rapport de A = T et C = G, et que la teneur en pourcentage
de A, T, G et C est diffÊrent pour diffÊrentes espèces.
Le modèle actuellement
acceptĂŠ de la structure Ă double hĂŠlice de l'ADN a ĂŠtĂŠ publiĂŠ en
1953 par Francis Crick et James Watson, sur la base des travaux de
Maurice Wilkins et Rosalind Franklin.
-

| Double
hĂŠlice de l'ADN. - L'ADN se prĂŠsente sous la forme d' une double
hÊlice antiparallèle. L'Êpine dorsale phosphatÊe (indiquÊe par les
lignes courbes) se situe Ă l'extĂŠrieur et les bases azotĂŠes Ă l'intĂŠrieur.
Chaque base d'un brin interagit via une liaison hydrogène avec une base
du brin opposĂŠ.
CrĂŠdit : Jerome Walker et Dennis
Myts. |
Structure en double
hĂŠlice de l'ADN.
Le diamètre de
la double hĂŠlice, 2 nm, est uniforme partout. Le sucre et le phosphate
se trouvent Ă l'extĂŠrieur de l'hĂŠlice, formant l'ĂŠpine dorsale de l'ADN.
Les bases azotĂŠes sont empilĂŠes Ă l'intĂŠrieur, comme les marches d'un
escalier, par paires; les paires sont liĂŠes les unes aux autres par des
liaisons hydrogène. Chaque paire de bases de la double hÊlice est sÊparÊe
de 0,34 nm de la paire de bases suivante. Un tour de l'hĂŠlice compte
dix paires de bases.
Les deux brins de
l'hĂŠlice courent dans des directions opposĂŠes, ce qui signifie que l'extrĂŠmitĂŠ
carbone 5' d'un brin fera face Ă l'extrĂŠmitĂŠ carbone 3' de son brin
correspondant. Ceci est appelÊ orientation antiparallèle. Cette
orientation est importante pour la rĂŠplication de l'ADN et dans de nombreuses
interactions avec les acides nuclĂŠiques.
Seuls certains types
d'appariement de base sont autorisĂŠs. Par exemple, une certaine purine
ne peut ĂŞtre associĂŠe qu'Ă une certaine pyrimidine. Cela signifie que
A peut ĂŞtre associĂŠ Ă T et que G peut ĂŞtre associĂŠ Ă C. En d'autres
termes, les brins d'ADN sont complĂŠmentaires les uns des autres. Si la
sĂŠquence d'un brin est AATTGGCC, le brin complĂŠmentaire aurait la sĂŠquence
TTAACCGG.
-

| ComplĂŠmentaritĂŠ
des bases azotĂŠes. - Dans une molĂŠcule d'ADN, les deux brins sont
antiparallèles l'un Ă l'autre de sorte qu'un brin s'ĂŠtend de 5' 'Ă
3' et l'autre de 3 'Ă 5'. L'ĂŠpine dorsale phosphatĂŠe est situĂŠe Ă
l'extĂŠrieur et les bases sont au milieu. L'adĂŠnine forme des liaisons
hydrogène (ou paires de bases) avec la thymine et les paires de bases
guanine avec la cytosine. |
La rĂŠplication
de l'ADN
Pendant la division
cellulaire, chaque cellule fille reçoit une copie de l'ADN par un processus
appelĂŠ rĂŠplication ou duplication de l'ADN. Comme l'a montrĂŠ
une expĂŠrience de Matthew Meselson et Franklin Stahl en 1958, lors de
la rĂŠplication de l'ADN chacun des deux brins d'ADN parentaux sert de
modèle pour le nouvel ADN à synthÊtiser; après rÊplication, chaque
ADN Ă double brin comprend un brin parental ou "ancien" et un "nouveau"
brin. C'est ce que l'on a appelĂŠ la rĂŠplication semi-conservatrice.
Diverses enzymes interviennent dans la facilitation de cette rĂŠplication
(hÊlicase, primase, ADN-polymÊrase, et ADN-ligase, cette dernière intervenant
spĂŠcialement dans la rĂŠparation des erreurs de rĂŠplication et dans la
recombinaison gĂŠnĂŠtique).
RĂŠplication
de l'ADN chez les procaryotes.
La plupart des procaryotes
contiennent un seul chromosome circulaire. La rĂŠplication chez les procaryotes
commence Ă partir d'une sĂŠquence trouvĂŠe sur ce chromosome appelĂŠe
l'origine de la rĂŠplication - le point auquel l'ADN s'ouvre. Une enzyme,
l'hĂŠlicase, ouvre la double hĂŠlice d'ADN, entraĂŽnant la formation de
la fourche de rĂŠplication. Les protĂŠines de liaison simple brin se lient
à l'ADN simple brin près de la fourche de rÊplication pour garder la
fourche ouverte. Une autre enzyme, la primase, synthĂŠtise une amorce d'ARN
pour initier la synthèse par l'ADN-polymÊrase, qui ne peut ajouter des
nuclĂŠotides que dans la direction 5 'Ă 3'. Un brin est synthĂŠtisĂŠ en
continu dans le sens de la fourche de rĂŠplication; c'est ce qu'on appelle
le premier volet. L'autre brin est synthĂŠtisĂŠ dans une direction ĂŠloignĂŠe
de la fourche de rĂŠplication, en de courts segments d'ADN appelĂŠs
fragments
d'Okazaki. Ce brin est connu sous le nom de brin retardĂŠ. Une
fois la rĂŠplication terminĂŠe, les amorces d'ARN sont remplacĂŠes par
des nuclĂŠotides d'ADN et l'ADN est scellĂŠ avec de l'ADN-ligase, ce qui
crĂŠe des liaisons phosphodiester entre le 3'-OH d'une extrĂŠmitĂŠ et le
phosphate 5 'de l'autre brin.
-

| Une
fourche de rĂŠplication est formĂŠe lorsque l'hĂŠlicase sĂŠpare les
brins d'ADN Ă l'origine de la rĂŠplication. L'ADN a tendance s' enrouler
davantage devant la fourche de rĂŠplication. La topoisomĂŠrase se casse
et rĂŠforme l'ĂŠpine dorsale du phosphate de l'ADN en avant de la fourche
de rĂŠplication, soulageant ainsi la pression qui rĂŠsulte de ce super-enroulement.
Les protĂŠines de liaison simple brin se lient Ă l'ADN simple brin pour
empĂŞcher l'hĂŠlice de se reformer. La primase synthĂŠtise une amorce d'ARN.
L'ADN polymĂŠrase III utilise cette amorce pour synthĂŠtiser le brin d'ADN
fils. Sur le brin principal, l'ADN est synthĂŠtisĂŠ en continu, tandis
que sur le brin retardĂŠ, l'ADN est synthĂŠtisĂŠ en courtes sĂŠquences
appelĂŠes fragments d'Okazaki. L'ADN-polymĂŠrase I remplace l'amorce d'ARN
par de l'ADN. L'ADN ligase scelle les espaces entre les fragments d'Okazaki,
reliant les fragments en une seule molĂŠcule d'ADN. (crĂŠdit : Mariana
Ruiz Villareal). |
RĂŠplication
de l'ADN chez les eucaryotes.
La rĂŠplication
chez les eucaryotes commence Ă plusieurs origines. Le mĂŠcanisme est assez
similaire Ă celui observĂŠ chez les procaryotes. Une amorce est nĂŠcessaire
pour initier la synthèse, qui est ensuite Êtendue par l'ADN-polymÊrase
lorsqu'elle ajoute des nuclĂŠotides un par un Ă la chaĂŽne en croissance.
Le brin principal est synthĂŠtisĂŠ en continu, tandis que le brin retardĂŠ
est synthĂŠtisĂŠ en courtes sĂŠquences, les fragments d'Okazaki. Les amorces
d'ARN sont remplacĂŠes par des nuclĂŠotides d'ADN; l'ADN reste un brin
continu en liant les fragments d'ADN avec l'ADN-ligase. Les extrĂŠmitĂŠs
des chromosomes posent un problème car la polymÊrase est incapable de
les ĂŠtendre sans amorce. La tĂŠlomĂŠrase, une enzyme avec une matrice
d'ARN intĂŠgrĂŠe, prolonge les extrĂŠmitĂŠs en copiant la matrice d'ARN
et en ĂŠtendant une extrĂŠmitĂŠ du chromosome. L'ADN-polymĂŠrase peut ensuite
Êtendre l'ADN à l'aide de l'amorce. De cette façon, les extrÊmitÊs
des chromosomes sont protĂŠgĂŠes.
La
rĂŠparation de l'ADN.
L'ADN-polymĂŠrase
peut faire des erreurs lors de l'ajout de nuclĂŠotides. Il modifie l'ADN
en relisant chaque base nouvellement ajoutĂŠe. Les bases incorrectes sont
supprimĂŠes et remplacĂŠes par la base correcte, puis une nouvelle base
est ajoutĂŠe. La plupart des erreurs sont corrigĂŠes au cours de la rĂŠplication,
bien que lorsque cela ne se produit pas, le mĂŠcanisme de rĂŠparation des
disparitĂŠs sot utilisĂŠ. Les enzymes de rĂŠparation des mĂŠsappariements
reconnaissent la base mal incorporÊe et l'extraient de l'ADN, en la remplaçant
par la base correcte. Dans encore un autre type de rĂŠparation, la rĂŠparation
par excision nuclĂŠotidique, la base incorrecte est supprimĂŠe avec quelques
bases Ă l'extrĂŠmitĂŠ 5 'et 3', et celles-ci sont remplacĂŠes en copiant
la matrice Ă l'aide de l'ADN-polymĂŠrase. Les extrĂŠmitĂŠs du fragment
nouvellement synthĂŠtisĂŠ sont attachĂŠs au reste de l'ADN Ă l'aide de
l'ADN-ligase, ce qui crĂŠe une liaison phosphodiester.
La plupart des erreurs
sont ainsi corrigĂŠes, mais celles qui ne le sont pas peuvent entraĂŽner
une mutation dĂŠfinie comme un changement permanent de la sĂŠquence
d'ADN. Les mutations peuvent ĂŞtre de plusieurs types, comme la substitution,
la suppression, l'insertion et la translocation. Des mutations peuvent
ĂŞtre induites ou se produire spontanĂŠment.
Les multiples visages
de l'ARN
L'acide ribonuclĂŠique,
ou ARN, est principalement impliquÊ dans le processus de synthèse des
protĂŠines
sous la direction de l'ADN. L'ARN est gĂŠnĂŠralement un simple brin et
est composĂŠ de ribonuclĂŠotides qui sont liĂŠs par des liaisons phosphodiester.
Un ribonuclĂŠotide dans la chaĂŽne d'ARN contient du ribose (sucre pentose),
l'une des quatre bases azotĂŠes (A, U, G et C) et le groupe phosphate.
Il existe quatre
principaux types d'ARN : l'ARN messager (ARNm), l'ARN ribosomal (ARNr),
l'ARN de transfert (ARNt) et le microARN (miARN).
L'ARN
messager.
Le premier, l'ARNm,
porte le message de l'ADN, qui contrĂ´le toutes les activitĂŠs cellulaires
dans une cellule. Si une cellule nÊcessite la synthèse d'une certaine
protÊine, le gène de ce produit est activÊ et l'ARN messager est synthÊtisÊ
dans le noyau.
La sĂŠquence de base
de l'ARN est complĂŠmentaire de la sĂŠquence codante de l'ADN Ă partir
de laquelle elle a ĂŠtĂŠ copiĂŠe. Cependant, dans l'ARN, la base T est
absente et U est prĂŠsente Ă la place. Si le brin d'ADN a une sĂŠquence
AATTGCGC, la sĂŠquence complĂŠmentaire de l'ARN est UUAACGCG.
Dans le cytoplasme,
l'ARNm interagit avec les ribosomes (structures Ă fonction catalytique,
composĂŠes d'ARN et de protĂŠines) et d'autres machines cellulaires.
L'ARNm est lu selon
des sĂŠquences de trois bases appelĂŠes codons.
Chaque codon code un seul acide aminÊ. De cette façon, l'ARNm est lu
et le produit protĂŠique est fabriquĂŠ.
L'ARN
ribosomal.
L'ARN ribosomal
(ARNr) est un constituant majeur des ribosomes sur lesquels l'ARNm se lie.
L'ARNr assure le bon alignement de l'ARNm et des ribosomes; l'ARNr du ribosome
a ĂŠgalement une activitĂŠ enzymatique (peptidyl-transfĂŠrase) et catalyse
la formation des liaisons peptidiques entre deux acides aminĂŠs alignĂŠs.
L'ARN
de transfert.
ComposĂŠ gĂŠnĂŠralement
de 70 Ă 90 nuclĂŠotides, l'ARN de transfert (ARNt) est l'un des plus petits
des quatre types d'ARN. Il transporte l'acide aminĂŠ appropriĂŠ jusqu'au
site de synthèse des protÊines. C'est l'appariement de bases entre l'ARNt
et l'ARNm qui permet Ă l'acide aminĂŠ correct d'ĂŞtre insĂŠrĂŠ dans la
chaĂŽne polypeptidique.
-

| MolĂŠcule
d'ARN de transfert ajoutant l'acide aminĂŠ phĂŠnylalanine Ă une chaĂŽne
polypeptidique en formation. L'anticodon AAG se lie au codon UUC sur l'ARNm.
La phĂŠnylalanine, un acide aminĂŠ, est attachĂŠe Ă l'autre extrĂŠmitĂŠ
de l'ARNt. |
Les
microARN.
Les microARN sont
les plus petites molĂŠcules d'ARN et leur rĂ´le implique la rĂŠgulation
de l'expression des gènes en interfÊrant avec l'expression de certains
messages d'ARNm.
Gènes et synthèse
des protĂŠines
Selon l'hypothèse proposÊe
par Crick dès 1958, il existe une relation entre l'ordre linÊaire des
nuclĂŠotides dans l'ADN et l'ordre linĂŠaire des acides aminĂŠs dans les
polypeptides (protÊines) à la synthèse desquelles il commande via l'ARN
messager.
On donne le nom de
code
gÊnÊtique à l'ensemble des règles qui dÊfinissent la manière
dont l'information nÊcessaire à la synthèse des protÊines est transmise
par l'ADN, et partant aux règles qui dÊfinissent la traduction des sÊquences
nuclĂŠotidiques en sĂŠquences d'acides aminĂŠs dans une protĂŠine.
Ce code est un "langage"
qui repose sur plusieurs "alphabets" : l'alphabet ADN (A, T, C, G),
l'alphabet ARN (A, U, C, G), et l'alphabet polypeptidique (20 acides
aminĂŠs).
Les "mots" sont composĂŠs
de trois nuclĂŠotides. Les triplets de l'ARNm sont appelĂŠs
codons
et ceux de l'ARNt sont appelĂŠs anticodons. Chaque codon dĂŠtermine
la nature de l'acide aminĂŠ qui sera synthĂŠtisĂŠ.
Le code gĂŠnĂŠtique
est dit redondant ou dĂŠgĂŠnĂŠrĂŠ, car les 4Âł = 64 codons possibles dans
l'ARNm ne spĂŠcifient que 20 acides aminĂŠs, un acide aminĂŠ donnĂŠ peut
ĂŞtre codĂŠ par plus d'un triplet, et il y a en outre trois codons dits
codons non-sens ou codons-stop, qui servent seulement Ă
signaler la fin d'une chaĂŽne polypeptidique.
Presque toutes les
espèces vivantes de la planète utilisent le même code gÊnÊtique.
-

| Le
code gÊnÊtique. - Ce tableau montre selon quelles règles chaque
triplet de nuclĂŠotides de l'ARNm est traduit en un acide aminĂŠ ou un
signal de terminaison dans une protĂŠine en formation.
(Source
: NIH). |
Si l'on poursuit
la mÊtaphore grammaticale, on dira que le code gÊnÊtique mène à la
construction de "phrases" : ce sont les gènes. Les gènes sont de petits
segments d'ADN qui contiennent une sĂŠquence dĂŠfinie de nuclĂŠotides contenant
toute l'information nĂŠcessaire pour fabriquer l'ARNm par un processus
nommĂŠ transcription. L'ARNm est ensuite utilisĂŠ pour synthĂŠtiser
les protĂŠines par le processus de traduction.
La transcription.
Transcription
procaryote.
Chez les procaryotes,
la synthèse d'ARNm est initiÊe au niveau d'une sÊquence promotrice sur
la matrice d'ADN comprenant deux sĂŠquences qui recrutent l'ARN-polymĂŠrase.
La polymĂŠrase procaryote consiste en une enzyme centrale de quatre sous-unitĂŠs
protĂŠiques et une protĂŠine sigma qui aide uniquement Ă l'initiation.
L'ĂŠlongation (allongement) synthĂŠtise l'ARNm dans la direction 5 'Ă
3' à un taux de 40 nuclÊotides par seconde. La terminaison libère l'ARNm
et se produit soit par interaction de la protĂŠine rhĂ´, soit par la formation
d'une bribe d'ARNm.
Transcription
eucaryote.
La transcription
chez les eucaryotes implique l'un des trois types de polymĂŠrases, selon
le gène transcrit. L'ARN-polymÊrase II transcrit tous les gènes codant
pour les protÊines, tandis que l'ARN-polymÊrase I transcrit les gènes
ARNr, et l'ARN polymÊrase-III transcrit l'ARN, l'ARNt et les petits gènes
d'ARN nuclĂŠaire. L'initiation de la transcription chez les eucaryotes
implique la liaison de plusieurs facteurs de transcription Ă des sĂŠquences
promotrices complexes qui sont gÊnÊralement situÊes en amont du gène
copiĂŠ. L'ARNm est synthĂŠtisĂŠ dans la direction 5 'Ă 3', et le complexe
FACT ( = facilitates chromatin transcription) se dĂŠplace et rĂŠassemble
les nuclĂŠosomes au fur et Ă mesure que la polymĂŠrase passe. Alors que
les ARN-polymĂŠrases I et III terminent la transcription par des mĂŠthodes
dĂŠpendant des protĂŠines ou de l'ARN en ĂŠpingle Ă cheveux, l'ARN-polymĂŠrase
II transcrit 1000 nuclÊotides ou plus au-delà de la matrice du gène
et clive l'excès pendant le traitement prÊ-ARNm.
Traitement
de l'ARN chez les eucaryotes.
Les prĂŠ-ARNm eucaryotes
sont modifiĂŠs avec une coiffe 5' en mĂŠthylguanosine et une queue poly-A.
Ces structures protègent l'ARNm mature de la dĂŠgradation et aident Ă
l'exporter du noyau. Les prĂŠ-ARNm subissent ĂŠgalement un ĂŠpissage, dans
lequel les introns sont retirĂŠs et les exons sont reconnectĂŠs avec une
prĂŠcision d'un seul nuclĂŠotide.
Seuls les ARNm finis
qui ont subi un coiffage 5', une polyadĂŠnylation 3' et un ĂŠpissage intron
sont exportĂŠs du noyau vers le cytoplasme. Les prĂŠ-ARNr et les prĂŠ-ARN
peuvent ĂŞtre traitĂŠs par clivage intramolĂŠculaire, ĂŠpissage, mĂŠthylation
et conversion chimique des nuclĂŠotides. L'ĂŠdition d'ARN est ĂŠgalement
effectuÊe, mais rarement, pour insÊrer des bases manquantes après la
synthèse d'un ARNm.
La traduction
Les acteurs de la
traduction en protĂŠine comprennent la matrice d'ARNm, les ribosomes, les
ARNt et diverses enzymes. Cette traduction s'effectue par les ribosomes,
sur la base de la sĂŠquence nuclĂŠotidique de l'ARNm, en utilisant des
triplets nuclĂŠotidiques (codons), qui sont traduits en acides aminĂŠs.
Chaque triplet de
nuclĂŠotides de l'ARN messager indique l'acide aminĂŠ Ă incorporer dans
la chaĂŽne polypeptidique qui se forme. La longueur de la protĂŠine synthĂŠtisĂŠe
sera donc proportionnelle Ă la longueur de l'ARNm mature.
L'ARNm entier est
traduit par Êtapes, codon après codon. Lorsqu'un codon non-sens est rencontrÊ,
un facteur de libÊration se lie et dissocie les composants et libère
la nouvelle protĂŠine. Le pliage de la protĂŠine se produit pendant et
après la traduction.
Les trois ĂŠtapes
principales de la traduction sont : l'initiation, l'ĂŠlongation et la terminaison.
L'initiation
ou dĂŠmarrage.
La traduction commence
au codon ou triplet d'initiation. Chez les eucaryotes, c'est gĂŠnĂŠralement
AUG, codant pour la mĂŠthionine; chez les procaryotes, il peut aussi s'agir
des triplets GUG (Val) et UUG (Leu) bien que moins efficacement. La petite
sous-unitĂŠ ribosomique se forme sur la matrice d'ARNm soit au niveau de
la sĂŠquence de Shine-Dalgarno (procaryotes) soit Ă l'extrĂŠmitĂŠ 5' (eucaryotes).
Une fois attachĂŠe
Ă l'ARNm, cette sous-unitĂŠ se dĂŠplace vers l'extrĂŠmitĂŠ 3' du messager
jusqu'Ă trouver le codon d'initiation. Un ARNt arrive avec l'anticodon
UAC (Met), puis la sous-unitĂŠ ribosomique principale arrive et, Ă partir
de ce moment, la formation de liaisons peptidiques pourra se produite entre
des acides aminĂŠs sĂŠquentiels spĂŠcifiĂŠs par la matrice d'ARNm selon
le code gÊnÊtique. Les ARNt chargÊs pÊnètrent dans le site ribosomal
A (Aminoacyl) et leurs acides aminĂŠs se lient avec l'acide aminĂŠ au site
P (Peptidyl).
L'ĂŠlongation.
L'ĂŠlongation est
le processus de synthèse de la protÊine proprement dit. Cette synthèse
s'effectue Ă partir de la lecture par la petite sous-unitĂŠ du ribosome
de la succession des codons de l'ARNm. Codon après codon, les acides aminÊs
sont formĂŠs et ajoutĂŠs Ă la chaĂŽne dĂŠjĂ constituĂŠe (polymĂŠrisation).
Ă chaque ĂŠtape,
le mĂŞme scĂŠnario se reproduit : le ribosome lit un nouveau codon de l'ARNm
exposĂŠ sur le site libre A. Un ARNt, disposant Ă une extrĂŠmitĂŠ de l'anticodon
complĂŠmentaire vient s'apparier au codon. L'acide aminĂŠ que cet ARNt
porte Ă son autre extrĂŠmitĂŠ se lie Ă l'acide aminĂŠ apportĂŠ par l'ARNt
prĂŠcĂŠdent et qui est lui-mĂŞme attachĂŠ Ă l'acide aminĂŠ ou aux acides
aminĂŠs dĂŠjĂ liĂŠs entre eux lors des cycles prĂŠcĂŠdents. Cette jonction
(une liaison peptidique) s'effectue grâce à une enzyme prÊsente sur
la grande sous-unitĂŠ du ribosome. L'ARNt peut maintenant se dĂŠtacher
pour laisser libre le site et permettre la lecture du codon suivant et
son appariement avec l'anticodon apportĂŠe par un autre ARNt, etc. Ainsi,
de proche en proche, la sĂŠquence d'acides aminĂŠs grandit-elle jusqu'Ă
l'apparition d'un signal d'arrĂŞt.
-

| Synthèse
d'une protĂŠine. - Un ribosome a deux parties: une grande sous-unitĂŠ
et une petite sous-unitĂŠ. L'ARNm se situe entre les deux sous-unitĂŠs.
Une molĂŠcule d'ARNt reconnaĂŽt un codon sur l'ARNm, s'y lie par appariement
de bases complĂŠmentaires et ajoute le bon acide aminĂŠ Ă la chaĂŽne peptidique
en croissance. |
La
terminaison.
Le processus se
termine lorsque le site A du ribosome est au-dessus d'un codon de
terminaison (l'un des trois triplets qui ne codent pour aucun acide aminĂŠ
: UAA, UAG et UGA). Les protĂŠines appelĂŠes facteurs de terminaison
qui se trouvent au site A entrent en scène, et la chaÎne protÊique formÊe
est libĂŠrĂŠe; tous les ĂŠlĂŠments qui ont contribuĂŠ au processus sont
sĂŠparĂŠs.
Les protĂŠines primaires
se replient pour atteindre des structures secondaires, tertiaires ou quaternaires
et acquièrent une fonctionnalitÊ biologique.
L'expression des
gènes.
Ă quelques exceptions
près - les globules rouges qui ne contiennent pas d'ADN dans leur Êtat
mature et certaines cellules du système immunitaire qui rÊorganisent
leur ADN en produisant des anticorps -, chaque cellule du corps contient
le même ADN. En gÊnÊral, cependant, les gènes qui dÊterminent par
exemple si un individu a les yeux verts, les cheveux bruns, et Ă quelle
vitesse il mĂŠtabolise les aliments sont les mĂŞmes dans les cellules de
ses yeux et de son foie, même si ces organes fonctionnent très diffÊremment.
Si chaque cellule a le mĂŞme ADN, comment se fait-il que les cellules ou
les organes soient diffÊrents? Pourquoi les cellules de l'oeil diffèrent-elles
si radicalement des cellules du foie?
Alors que chaque
cellule partage le mĂŞme gĂŠnome et la mĂŞme sĂŠquence d'ADN, chaque cellule
n'exprime pas le même ensemble de gènes. Chaque type de cellule a besoin
d'un ensemble diffĂŠrent de protĂŠines pour remplir sa fonction. Donc,
seul un petit sous-ensemble de protĂŠines est exprimĂŠ dans une cellule.
Pour que les protĂŠines s'expriment, l'ADN doit ĂŞtre transcrit en ARN
et l'ARN doit ĂŞtre traduit en protĂŠine. Dans un type de cellule donnĂŠ,
tous les gènes codÊs dans l'ADN ne sont pas transcrits en ARN ou traduits
en protĂŠines car des cellules spĂŠcifiques de notre corps ont des fonctions
spĂŠcifiques. Les protĂŠines spĂŠcialisĂŠes qui composent l'oeil (iris,
cristallin et cornĂŠe) ne sont exprimĂŠes que dans l'oeil, tandis que les
protĂŠines spĂŠcialisĂŠes du coeur (cellules du stimulateur cardiaque,
muscle cardiaque et valves) ne sont exprimĂŠes que dans le coeur. Ă un
moment donnÊ, seul un sous-ensemble de tous les gènes codÊs par notre
ADN sont exprimÊs et traduits en protÊines. L'expression de gènes spÊcifiques
est un processus hautement rĂŠgulĂŠ avec de nombreux niveaux et ĂŠtapes
de contrôle. Cette complexitÊ garantit une bonne expression du gène
dans la cellule appropriĂŠe au bon moment.
Pour qu'une cellule
fonctionne correctement, les protĂŠines nĂŠcessaires doivent ĂŞtre synthĂŠtisĂŠes
au bon moment et au bon endroit. Toutes les cellules contrĂ´lent ou rĂŠgulent
la synthèse des protÊines à partir des informations codÊes dans leur
ADN. Le processus d'activation d'un gène pour produire de l'ARN et des
protĂŠines est appelĂŠ expression gĂŠnique. Que ce soit dans un
organisme unicellulaire simple ou dans un organisme multicellulaire complexe,
chaque cellule contrôle quand et comment ses gènes sont exprimÊs. Pour
que cela se produise, il doit y avoir des mĂŠcanismes chimiques internes
qui contrôlent quand un gène est exprimÊ pour produire de l'ARN et des
protĂŠines, quelle quantitĂŠ de protĂŠines est produite et quand il est
temps d'arrĂŞter de produire cette protĂŠine parce qu'elle n'est plus nĂŠcessaire.
La rĂŠgulation de
l'expression des gènes demanderait une quantitÊ importante d'Ênergie
si un un organisme devait exprimer chaque gène à tout moment. Il est
donc plus Êconome en Ênergie de n'activer les gènes que lorsqu'ils sont
nÊcessaires. De plus, l'expression d'un sous-ensemble de gènes dans chaque
cellule permet d'ĂŠconomiser de l'espace car l'ADN doit ĂŞtre dĂŠroulĂŠ
de sa structure ĂŠtroitement enroulĂŠe pour transcrire et traduire l'ADN.
Les cellules devraient ĂŞtre ĂŠnormes si chaque protĂŠine ĂŠtait constamment
exprimĂŠe dans chaque cellule.
Le contrĂ´le de l'expression
des gènes est extrêmement complexe. Les dysfonctionnements de ce processus
sont prĂŠjudiciables Ă la cellule et peuvent conduire au dĂŠveloppement
de nombreuses maladies, y compris Ă celui du cancer. |
